I posted this tweet a couple of weeks ago and thought I'd explain it a bit more.
2018 is going to be a defining year. Either it'll be the end and a new beginning, or it'll be a revival. Not sure I control either path other than my desire to not walk it alone.
I wrote it shortly after posting the final bits for the CDT 9.4 release and was starting to think about my plans for 2018. And certainly the current state of Eclipse tools projects including the CDT has been weighing on my mind.
When QNX started the CDT project, we embraced open source as a means of sharing in a common effort to build a great C/C++ IDE. We didn't have a huge team and we knew that many platform vendors were in a similar situation. By working together, we all benefit. And for many years it worked and we now have the embedded industry's most popular IDE that we all should be proud of.
But times they are a changing. As I blogged last year around this time, web technologies are becoming the platform of choice, not just for web, but with the help of Electron, for the desktop as well. We can not discount the popularity of Visual Studio Code and the ecosystem that has quickly developed around it. And with shared technologies like language servers, the door is being opened to choice like we've never had before.
So as I was inferring from my tweet, it's time to take stock of where we are and where we are going. I was encouraged with the discussions I had at EclipseCon around the future of CDT. I've done what I can to help keep things rolling but at the end of the day the community leads the way and I need to be honest with myself and my customers and go where they go.
The new year brings a big change; I will be leaving the Eclipse Foundation at the end of January. This has been a difficult decision to make but it is time to take on a new challenge.
I am extremely proud to have been part of the Eclipse Foundation and Eclipse community since the early days. I fondly remember the chaotic and exciting early years of setting up the Foundation and the explosive growth of projects, members and users. The Eclipse Foundation was one of the first open source foundations that showed how professional staff can help bring together companies and open source developers to create innovative open source communities. In some ways, the Eclipse Foundation became the template for many of the new open source foundations started in the last 5 years.
It is great to be leaving when the Foundation is gaining tremendous momentum. In particular, EE4J, Eclipse Microprofile, DeepLearning4J, OpenJ9 and other projects are all showing Eclipse is becoming the place for open source enterprise Java. The Eclipse IoT working group continues to grow and is certainly the largest IoT open source community in the industry. The Foundation is definitely on a roll.
Of course I will miss the amazing people at the Foundation and in the Eclipse community. I am privileged to have worked with so many individuals from many different organizations. One of the best parts of my role is being able to learn from some of the world’s best.
It is time to start looking for a new challenge. I am going to take some time to look for a new position. My passion is working with smart technologists to create and implement strategies to promote the market adoption of new technologies and solutions. Today there are some fascinating new technologies being introduced, like AI/ML, Blockchain/Distributed Ledgers, Cloud Native Computing, IoT, etc. It is an exciting time to work in the technology industry and I look forward to taking on a new challenge.
My last day with the Eclipse Foundation will be January 26, 2018. The technology industry is very small so I hope and expect to keep in touch with many people from the Eclipse community. I will continue to be active on my blog, Twitter and LinkedIn.
New Features, more languages, better symmetry and other improvements
Eclipse Collections is a collections framework for Java. It has optimized List, Set and Map implementations with a rich and fluent API. The library provides additional data structures not found in the JDK like Bags, Multimaps and BiMaps. The framework also provides primitive versions of Lists, Sets, Bags, Stacks and Maps with a rich and fluent API. There is support for both Mutable and Immutable versions of all containers in the library.
The Eclipse Collections community continues to grow. There were ten developers who contributed to the Eclipse Collections 9.1.0 release. I want to thank everyone who made a contribution. If this was your first contribution to an open source project, congratulations and welcome!
The release notes for Eclipse Collections 9.1.0 are here:
In addition to code contributions, several developers worked on translating our Eclipse Collections Website to other spoken languages. This is an amazing example of how you can use more than just your coding skills to help open source projects. Thank you to both the contributors and reviewers!
A Chinese translation is in the works, and we will be looking to add other languages in the future. Please feel to submit an issue or pull request if you’d like to work on a translation to a spoken language you are fluent in.
The Eclipse Collections Katas
Both of the Eclipse Collections katas are now available in Reveal.js as of this release.
We also had our first ever contribution of a live video demonstration of the Eclipse Collections Pet Kata using Eclipse Oxygen presented in Brazilian Portuguese. Great work and thank you Leo!
It would be great to have multi-language translations of our katas as well. Our katas are hosted now as simple markdown files which get translated to web based slides using Reveal.js. Feel free to submit a pull request if you’d like to translate the katas to another spoken language.
New Collectors
Several new Collector implementations were added to the Collectors2 utility class in this release. We continue to look to provide good integration between the Streams library and Eclipse Collections. Here’s an example of using the new countBy Collector with a Stream of String.
There is a zip<Type> method for each primitive type. Here is an example of the zipChar method available on CharAdapter, which is an ImmutableCharList. We can obtain a CharAdapter now simply by using the new Strings factory class.
@Test public void zipCharToChar() { ImmutableList<CharCharPair> zipped = Strings.asChars("hello") .zipChar(Strings.asChars("hello").asReversed());
Sometimes providing good symmetry may not be the best solution to a problem. There has been a method called zipWithIndex available on Eclipse Collections object collections for a very long time. ZipWithIndex was added before we had primitive collections in Eclipse Collections, so its return type unfortunately boxes an Integer for the index. I did not want to add a primitive version of of the same API. Instead, I added a new method to both object and primitive Lists (Symmetry!) called collectWithIndex. CollectWithIndex can be used to implement zipWithIndex by collecting to a ObjectIntPair.
@Test public void whereIsZipWithIndex() { MutableList<Pair<String, Integer>> original = Lists.mutable.with("1", "2", "3") .zipWithIndex();
Ideally, zipWithIndex would have returned ObjectIntPair, but this type wasn’t available when the API was originally added. Since we don’t like breaking backwards compatibility on existing methods unless there is a very compelling reason to, we’ll probably never change the return type for zipWithIndex. The collectWithIndex method can return any type you want, not just a Pair. I believe collectWithIndex will prove to be a more useful method than zipWithIndex in the long run.
And of there is more…
Have a look at some of the other features listed in the release notes. We look forward to seeing more contributors to Eclipse Collections in the future.
Happy New Year and have fun using Eclipse Collections 9.1 in your Java projects!
Hazelcast, a provider in open source In-Memory Data Grid (IMDG), recently joined the Eclipse Foundation to work with the other members of the Eclipse community to mainly focus on JCache, Eclipse MicroProfile, and EE4J. Greg Luck, CEO at Hazelcast, spoke to InfoQ about Hazelcast joining the Eclipse Foundation.
The output is a report used to assess and prioritize migration and modernization efforts.
The RHAMT Eclipse Plugin - What does it do?
Consider an application migration comprised of thousands of files, with a myriad of small changes, not to mention the tediousness of switching between
the report and your IDE. Who wants to be the engineer assigned to that task? :)
Instead, this tooling marks the source files containing issues, making it easy to organize, search, and in many cases automatically fix issues using quick fixes.
Let me give you a quick walkthrough.
Ruleset Wizard
We now have quickstart template code generators.
Rule Creation From Code
We have also added rule generators for selected snippets of code.
Ruleset Graphical Editor
Ruleset navigation and editing is faster and more intuitive thanks to the new graphical editor.
Ruleset View
We have created a view dedicated to the management of rulesets. Default rulesets shipped with RHAMT can now be opened, edited, and referenced while authoring
your own custom rulesets.
Run Configuration
The Eclipse plugin interacts with the RHAMT CLI process, thereby making it possible to specify command line options and custom rulesets.
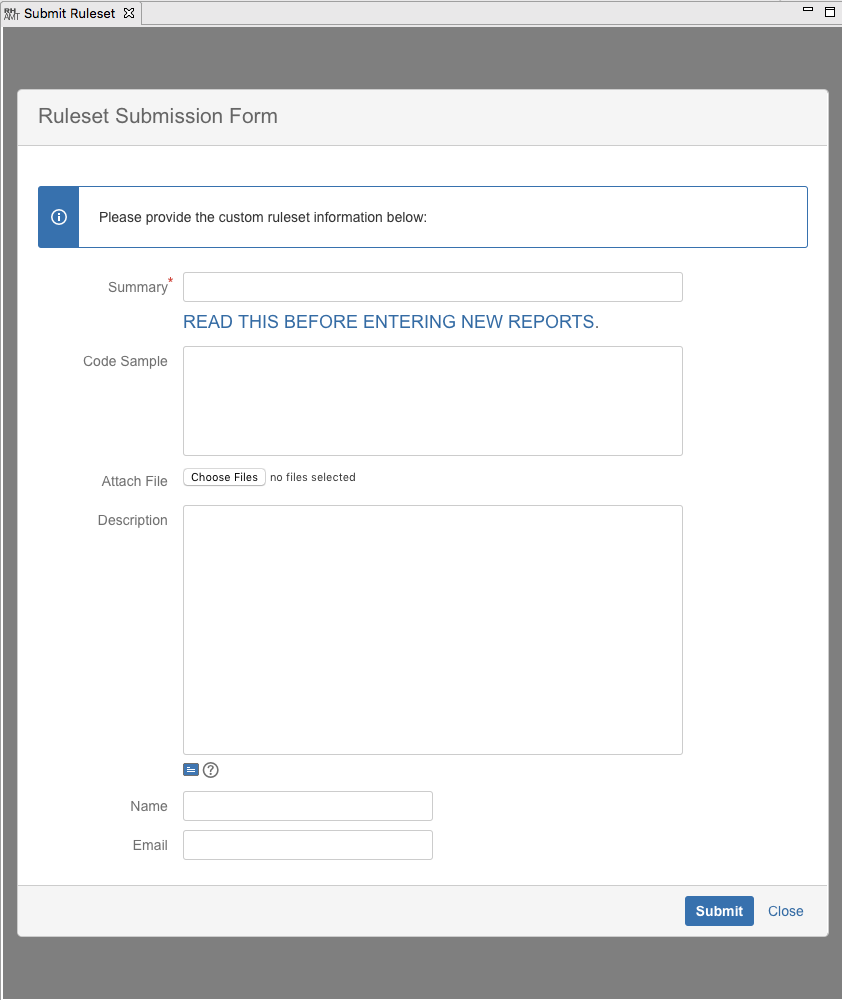
Ruleset Submission
Lastly, contribute your custom rulesets back to the community from within the IDE.
Do you have to debug an existing SWT view and you are not sure what elements are really on screen? Are you tired of manually coloring composites to find out what’s wrong in your layout?
It is time to remember an oldie but goodie: The SWT spy!
It is a fairly old tool, but still very useful, so let us have a quick look.
Spy can augments a running tool and provide valuable information to debug any SWT application. This can be the IDE in case you are a plugin developer or any RCP or Eclipse 4 application. You can get SWT spy from this location:
http://download.eclipse.org/eclipse/updates/4.7
Either add it to your target platform or directly install it into your IDE.
In case you install SWT spy into the IDE, you can open it by pressing:
SHIFT+CTRL+ALT+F9
If you would like to use SWT spy in a custom application, you need to include the bundle “org.eclipse.tools.layout.spy” into your product. To trigger the spy, there are two options:
If you run on the compatibility layer (3.x), the key binding will also work
If you are running on Eclipse 4, you can embed the following code to open the SWT spy window:
final LayoutSpyDialog popupDialog = new LayoutSpyDialog(shell);
popupDialog.open();
The SWT spy will open as a separate dialog, which is connected to the running application. It allows for the inspection of any SWT element with a focus on layout information. To navigate you can either browse the hierarchy or directly jump to an element. The hierarchy is shown as a list on the left side. By double clicking on an element within the current container you will walk down the SWT widget tree, the button on the top left corner will send you one level up. To jump to a specific element, click the button “Select Control” and hover over any element in the running application. A yellow border will help you with the selection. If you check the option “Show overlay”, SWT spy will draw a yellow border around the currently selected element.
The text field on the right side shows the layout data of the current parent composite. If you select an element on the left, you see its layout data in the text field below. This is very helpful to debug layouts. Furthermore, you can use existing layouts as a template. The SWT spy directly shows you how to create the layout data for a selected element, e.g.
During our work on EMF Forms, we often develop or adapt renderers. The goal of EMF Forms is to ease the creation of forms, especially concerning the layout. However, before this can happen, you must first create a renderer which will take care of the layout for you. EMF Forms ships with default layouts, but you might want to adapt them.
When debugging the layout of a combination of renderers, it is often helpful to visualize all elements, which are on screen. Sometimes, elements are not visible (e.g. composites) or have the same background color as their parent. For this purpose, the SWT spy allows you to color controls. If you check the option “Color controls …”, the spy will assign different background colors to each level in your widgets tree. This looks ugly, but is helpful in finding hidden composites or to see how much space certain elements occupy.
We are pleased to announce the seventeenth release of Orion, “Your IDE in the Cloud”. You can run it now at OrionHub, from NPM or download the server to run your own instance locally.
Once again, thank you to all committers and contributors for your hard work this release. There were 86 bugs and enhancements fixed, across 248 commits from 13 authors!
This release was focussed entirely on making compatibility, stability and overall quality improvements to the Node.js server.
Hi folks! Some of you might have seen my earlier blogpost on Machine Learning Formatting. It was more or less meant as an advertiser for the Eclipse Democamp Munich. As promised, here comes the follow up blogpost with more details.
Codebuff is a project started by Terrence Parr. The project aims the problem that writing a codeformatter is hard and will not fit all needs. Therefore people want to customize it in every way since formatting is a very individual thing.
Codebuff tries to format code by taking already formatted examples and learning out of that how to format code based on the same grammar. To do that it needs the corresponding lexer and parser. The lexer is used to get the tokens and the parser to create an abstract syntax tree out of the tokens. Based on that information Codebuff tries to mimics the behavior of a developer. Sounds simple, but how does that work? First of all code consists of tokens.
Depending on tokens and the location a developer would normally make a decision to introduce or delete whitespaces. A whitespace could be a simple space, a newline along with an indentation or alignment. Another valid decision could also be to do nothing. To make a decision you need certain criteria. Codebuff works with 21criterias, so called features that are taken into account. The following figure shows the 5 most obvious features.
Based on those 21 features Codebuff analyses the given examples and computes token properties.
When training is done all token properties are stored as vectors in a matrix along with the whitespace information.
From this point on we should start to speak about machine learning. What we want to achieve is finding a match in the computed matrix of token properties and get the whitespace to inject into the given document at a certain position.
First of all we have to compute where to look at in the examples. For that reason we look at our current position in the document and compute the token property (vector) like we did it in the training without storing it to the matrix.
Now that we have that vector we need an algorithm to find a match in the matrix and apply the right whitespace to the document.
For doing that Codebuff uses the simplest machine learning algorithm that exists – the K-nearest neighbors algorithm. The algorithm uses a function to compare a token property to the entries of the existing training-matrix. To do that the a constant named k needs to be specified to define how many nearest neighbors should be used. Mostly k is computed once by taking the root of the number of examples in the corpus, but for Codebuff k is fixed to 11.
As shown above, experiments with different languages showed that the median error rate is nearly constant from k = 11 on, so taking this as a constant makes sense for performance reasons.
As we now know the value of k, we can start to find most similar token properties to the one we just computed at the location to format.
Out of that the algorithm uses a function to weigh the best whitespace. In Codebuff it takes simply the whitespace that appears most often – very simple but efficient. Codebuff's theoretical background is explained in more depth here and you can find an entertaining talk by Terence on YouTube.
Looking at the way Codebuff works you might ask yourself how many example files you need to get good results? The answer is pretty simple: after a lot of experiments the Codebuff guys found out that from 10 example files on the results will not get better nor worst. The next figure shows for some different languages that after 10 files the error rate stays around the same.
So – what has Codebuff to do with Xtext?
Now as we know a bit of the theoretical background around Codebuff you may wonder what all that stuff has to do with Xtext.
In Xtext you can create various DSLs for very different domains. For each language you need to specify a formatter. Luckily Xtext comes with two different APIs. The older one relies on tokens only, that means you can define how your DSL should be formatted on a lexical level. The newer API relies on the semantic model in addition. Depending on the state of the abstract syntax tree you can treat things different. Cool – but customization of your formatter is not coming out of the box and we know that formatting is an individual thing. So you would end up in a lot of effort to write a reasonable formatter and make customizations possible. Even when you did your best you will always find a special case that someone wants to treat differently. Codebuff sounds like a nice idea to solve that problem...
To marry Xtext and Codebuff together you don't need to do much. Ok – Xtext relies on AntLR 3 and bringing AntLR 4 on the classpath will take you into hell, but there is a pragmatic way around that.
DISCLAIMER: From this point on we are talking about a prototype – not ready for production!
First we wrote a so-called GeneratorFragment. To understand this you would have to understand how Xtext works under the covers, but for now let's just stay with the fact that Xtext generates it's DSL specific infrastructure out of the Xtext grammar and a GeneratorFragment is one piece of the overall generator.
To come back to our issue – the GeneratorFragment needs to generate an AntLR 4 grammar. Out of that we need to generate the AntLR 4 lexer and parser. To do that we need the AntLR 4 generator but we are not allowed to bring that stuff on the classpath. Let's assume we managed to do that – how could we compile the generated code without AntLR 4 on the classpath? Even when we managed that we are not allowed to bring Codebuff on the classpath as it carries AntLR 4 under the covers. Even when we managed that – does Codebuff have an API that fits for us? The documentation just deals with a call of a main method with a bunch of parameters....
Ok – step by step.
1. Generate the grammar
The major difference between AntLR 3 and 4 is that AntLR 4 does not allow syntactic predicates anymore since it handles left recursion now directly. AntLR 3 is not able to do that and for that reason grammars need to be left refactored. By doing that, syntactic predicates guide the parser on it's way to get rid of ambiguities and make decisions. The other thing is that the syntax has changed a bit from AntLR 3 to 4. Beside that Codebuff has a special need. Whitespaces and comments need to go to the hidden channel.
2. Generate lexer and parser
To achieve that we are downloading the necessary jar on demand once, like we already do it in Xtext for AntLR 3. To invoke the so called Tool of AntLR 4 we created a URLClassLoader that points to the jar. As Xtext uses AntLR 3 we need to leave the parent classloader empty to avoid confusions. After that we need to use reflection to call the right API.
As a fun fact we observed that the AntLR 4 Tool has two methods to process a grammar and both produce lexer and parser - but they are not equal. After fighting with that situation we found out that the method process is not the right choice as Codebuff got stuck with that the generated sources. ProcessGrammarsOnCommandLine produced the right result since it reorders the tokens by calling sortGrammarByTokenVocab and then called process.
Of course the generated classes are stored in a separated folder that is no source folder. Otherwise we would end up in compile errors in the project. ;-)
3. Compile lexer and parser
We cannot simply compile the lexer and parser like the rest of the code since AntLR 4 is not on the classpath. To achieve compiling we used the javax.tools.JavaCompiler directly. To use it we need to bring referenced classes into a special classloader. For this use-case the AntLR 4 jar is enough. After that we need to handle in the files to compile - that's it. Of course the compiled class files are stored in a separated folder as well. ;-)
4. Use Codebuff with the compiled classes without bringing it on the classpath
To achieve that we used the same trick as for AntLR 4 and downloaded Codebuff on demand once. So we ended up in two jars, AntLR 4 and Codebuff, a grammar and compiled lexer and parser. Now we need to combine all those things.
Codebuff does not really have an API to use it somewhere else then the commandline. Normally the Tool class needs a bunch of information including a destination file.
The formatter API in Xtext does not write to a file directly. It needs to set the formatted text as a string. Because of that the given approach does not work for use. We digged a bit in the code and yes there is a way that is slightly complicated and as you know we have to do everything through reflection ;-)
To explain it in a simple way we will just mention the steps without showing the ugly reflective code.
We need to instantiate a org.antlr.codebuff.misc.LangDescriptor that holds all necessary information about the language. That includes the folder of the examples, a regex to identify examples, the compiled lexer and parser, the root rule of the grammar, the amount of spaces that make an indentation and the rule for comments.
We need to load all examples to invoke the train method that fills the matrix with token properties.
We need to parse the document that we want to format.
We need to instantiate the formatter and fill in the necessary information including the training result.
We need to invoke the formatter to get a string back that represents the formatted document.
Sounds simple but we have to admit that it was pain. If Codebuff would have a more user friendly API, it would have been much simpler – we are planning to create a pullrequest to Codebuff to make it easier.
On Xtext side the story is simple – we need to bind a org.eclipse.xtext.ui.editor.formatting.IContentFormatterFactory to create our org.eclipse.jface.text.formatter.IContentFormatter that has only one method that gets the document that holds all necessary information and we can directly set the new formatted text.
The only tricky part that is left is classloading. We need to have Codebuff, AntLR4 and the compiled lexer and parser in a classloader. Of course a URLClassLoader solves the problem as we already downloaded the necessary jars and compiled the lexer and parser.
As a wrap up we can say that Codebuff creates a nice way to get rid of an old problem – but it's not perfect. For the future of Xtext it would be nice to have something like that included. Currently we are looking into alternative approaches and enhancements of the existing Codebuff codebase. Stay tuned.
Last week the EE4J project achieved an important milestone when the source code for the API and reference implementation of JSON-P JSR-374 project was pushed by Dmitry Kornilov into its GitHub repository in the EE4J organization. This is the first project of the initial nine proposed to reach this stage.
This may seem like a small step in a very large process, but it is a concrete demonstration of the commitment to move forward with the migration of Java EE to the Eclipse Foundation. The Oracle team and the Eclipse Foundation staff had a ton of work to do to make this possible. This is definitely one of those cases where the visible code contributions are just the visible tip of an iceberg’s worth of effort.
Here are just a few examples of the work that went on to get to this stage:
The names of the projects such as Glassfish represent important trademarks in the industry. Oracle transferred ownership of these project names to the Eclipse Foundation so that they can be held and protected for the community.
The EMO staff reviewed the projects proposals, ran the project creation review, provisioned the repositories and set up the committer lists.
The Oracle team packaged up the source code and updated the file headers to reflect the new EPL-2.0 licensing.
The EMO IP staff scanned the code and ensured that all was well before approving it for initial check-in.
Now that the collective team has run through this process with JSON-P we will be working to get the remaining eight initial projects pushed out as quickly as possible. Hopefully by the end of this month. Meanwhile, more projects will be proposed and we will be migrating a steady stream of Java EE projects into EE4J.
It was a crazy 2017 for me with 300,000 miles of business travel, but it was all worth it to experience every major cloud provider adopt Kubernetes in some fashion and grow our community to 14 projects total! Also, it was amazing to help host 4000+ people in Austin for KubeCon/CloudNativeCon, where it actually snowed!
I’d like to share some personal take aways I had from the conference (of course with accompanying tweets) that will serve as predictions for 2018:
Exciting Times for Boring Container Infrastructure!
One of the themes from the conference was that the Kubernetes community was working hard to make infrastructure boring. In my humble opinion, Kubernetes becomes something like “POSIX of the cloud” or “Linux of the Cloud” where Kubernetes is solidifying kernel space but the excitement should be in user space.
In 2018, look for the boring infrastructure pattern to continue, the OCI community is planning to make distribution a bit more boring via a proposed distribution API specification. I also predict that some of the specialized/boutique cloud providers who haven’t offered Kubernetes integration will do so finally in 2018.
CNCF + KubeCon and CloudNativeCon: Home of Open Infrastructure
CNCF has a community of independently governed projects, as of today which there are 14 of covering all parts of cloud native. There’s Prometheus which integrates beautifully with Kubernetes but also brings modern monitoring practices to environments outside of cloud native land too! There’s Envoy which is a cloud native edge and proxy, that integrates with Kubernetes through projects like Contour or Istio, however, Envoy can be used in any environment where a reverse proxy is used. gRPC is a universal RPC framework that can help you build services that run on Kubernetes or any environment for that matter! There are many other CNCF projects that have use cases outside of just purely a cloud native environment and we will see more of that usage grow over time to help companies in transition to a cloud native world.
In 2018, look for CNCF conferences continue to grow, expand locations (hello China) and truly become the main event for open source infrastructure. In Austin it was incredible to have talks and people from the Ansible to Eclipse to JVM to Openstack to Zephyr communities (and more). I can’t think of any other event that brings together open source infrastructure across all layers of the cloud native landscape.
Moving up the Stack: 2018 is Year of Service Meshes
Service meshes are fairly a new concept (I highly recommend this blog post by Matt Klein if you’re new to the concept) and will become the middleware of the cloud native world. In CNCF, we currently host Envoy and linkerd which helped poineer this space. In 2018, I expect more service mesh related projects to be open sourced along with more participation from traditional networking vendors. We will also see some of the projects in this space to mature with real production usage.
Cloud Native AI + Machine Learning: Kubeflow
In 2018, ML focused workloads and projects will find ways to integrate with Kubernetes to help scale and encourage portability of infrastructure. Just take a look at the kubeflow project which aims to make ML with Kubernetes easy, portable and scalable. Note, this doesn’t mean that AI/ML folks will have to become Kubernetes experts, all this means is that Kubernetes will be powering more AI/ML workloads (and potentially even sharing their existing cloud native infrastructure). I expect more startups to form in this space (see RiseML as an example), look to see a “cloud native” AI movement that focuses on portability of workloads.
Developer Experience Focus and Cloud Native Tooling
One of my favorite keynotes from KubeCon was Brendan Burns speaking about metaparticle.io, a standard library for cloud native applications. I completely agree with his premise that we need to democratize distributed systems development. Not everyone developer needs to know about Kubernetes the same way not every developer needs to understand POSIX. In 2018, we are going to see an explosion of open source “cloud native languages” that will offer multiple approaches to democratizing distributed systems development.
Also in 2018, I expect us to see growth in cloud native development environments (IDEs) to provide better developer experience. As an example, for those that were wondering why there was an Eclipse Foundation booth at KubeCon, they were demoing a technology called Eclipse Che which is a cloud native IDE framework (your workspace is composed of docker/container images). Che is a framework that helps you build Cloud Native IDEs too, for example, OpenShift.io is OpenShift integrated with Che to provide you a fully blown online development experience.
Finally in 2018, I expect the developer experience of installing Kubernetes applications improved, including the underlying technology for doing so. For example, the Service Catalog work and websites like kubeapps.com showcase what is possible in making it easier for people to install Kubernetes app/integrations, we’ll see this grow significantly in 2018. Also I predict that the Helm community will grow faster than it has before.
Diversity and Inclusion
One of my favorite take aways from the conference was the focus on diversity and inclusion within our community:
We (thank you amazing diversity committee) raised $250,000 and helped over 100 diversity scholarship recipients attend KubeCon/CloudNativeCon in Austin. In 2018, I predict and truly hope some other event will match or beat this.
Anyways, after a crazy 2017, I can’t wait to grow our communities in 2018.
The Papyrus layers functionality has been in incubation for a while, and some may be wondering what it’s all about:
The Layers mechanism allows to build different views of an underlying UML diagrams by applying selections rules as well as graphical transformation operators.
You can read the description of this function in the Papyrus Wiki, and you can also see it in action in this YouTube video:
Note that they only index my semantic model (i.e., the “.uml” files) and not the diagrams, which makes sense in their context given that diagrams are not semantic elements.
As 2018 begins I would like to share a few thoughts on where I think the Eclipse community is heading. I am looking forward to an incredibly busy year for myself, the staff of the Eclipse Foundation, and our community, because this is going to be a year of tremendous growth and opportunity. I will try to give a brief overview of what I see as some of the exciting things that are going on at the Eclipse Foundation. I am sure that I will miss some, so apologies in advance!
Of course the big news of the past few months was theannouncement by Oracle that Java EE is going to be moving to the Eclipse Foundation. This represents the largest single contribution to the Eclipse community since — well, the original Eclipse IDE project in 2001. It is approximately 35 new projects, hundreds of new committers and contributors, and millions of lines of code. It is and was an incredible endorsement of the Eclipse Foundation’s mission as the leading organization for individuals and companies to collaborate on commercial-friendly open source software. Since the announcement in September, we have created the new Eclipse Enterprise for Java (EE4J) top-level project, and source code is starting to move into the projects. During 2018 our collective mission will be to create a functioning and successful community around this code, pick a new brand to replace Java EE going forward, ship a release compatible with Java EE 8, open source the Java EE TCKs, and establish a new specification process to shape the future of cloud native Java. I feel out of breath just thinking of it.
But in addition to this Java EE work, it is clear that the Eclipse Foundation is now playing a pivotal role in the future of the Java ecosystem. Projects such asEclipse MicroProfile (microservices for Java),Eclipse OpenJ9 (Java virtual machine),Eclipse DeepLearning4J (machine learning),Eclipse Collections (highly scalable collections),Eclipse JNoSQL (NoSQL for Java EE) andEclipse Vert.x (reactive apps for Java) are leading the next generation of Java innovation.
From the Eclipse Science community comesEclipse XACC, which I believe is the world’s first community-led open source project in the new field of quantum computing. Originating from Oak Ridge National Laboratory, XACC is working to integrate quantum processors with the high-performance computing environments that are the backbone of modern scientific computing. It will be exciting to see XACC ship its first release in 2018, and to support its desire to create an open collaboration to shape the next generation of computing hardware and programming paradigms.
The Eclipse IoT community has been a significant growth area within the Eclipse community over the past couple of years. In 2017 Eclipse IoT grew to over 25 projects, and is attracting a substantial developer and corporate community.. It is also a terrifically ambitious group, with avision of providing technology stacks that span the smallest of constrained devices, through device gateways, to cloud-scale data collection and management runtimes. Late in 2017 the group published awhite paper on the role that open source will play in Industry 4.0, or industrial IoT. This white paper is important because in many ways it sets out the vision for the group, which has been primarily focused on industrial IoT. In 2018 the primary goal for Eclipse IoT is to start shipping these stacks rather than simply projects. In other words, to create cross-project collaborations that provide IoT adopters with more complete solutions rather than individual building blocks. This will go a long way to paving the way for broad industry adoption of these open source IoT technologies.
Finally, a word on developer tools — the Eclipse Foundation’s original franchise. I noticed recently that according to at leastone source, the Eclipse IDE is maintaining its position as the #1 IDE in the world, and grew its market share substantially last year. The goal for this year is to continue this trend. In addition, theEclipse Che cloud IDE continues to grow its community and adoption. As more and more developers work on cloud native applications, the appeal of a cloud IDE that works where they do is going to grow. Che is well positioned to be the leader in this space and is the only community-led cloud IDE.
Anyone who has seen me speak over the past couple of years has likely heard me express the idea that the “community is the capacity.” The Eclipse Foundation is a 30 person organization that supports a community of hundred of projects, hundreds of members, thousands of committers and contributors, and millions of users. Whenever I take a moment to reflect on what we accomplish together it is breathtaking. The breadth of the technology that we collectively produce is vast, and our community spans the globe. Equally exciting, engagement continues to grow with a variety of industries notably automotive, power, transportation, etc. interested in leveraging the Eclipse Foundation as the place for open, commercial collaboration.
I am incredibly optimistic that 2018 is going to be one of the most exciting years we’ve ever had, so please get involved!
There is a lot going on as Java EE continues its migration to the Eclipse Foundation. Since there are so many parallel threads, I thought it would be a good idea to recap where we are, and what is coming up in the next few weeks.
First off, we are continuing to work on arriving at a new brand name. Last week the PMC provided the Eclipse Foundation with a potential list of names, and we are running trademark reviews to see if we believe that they can be properly secured. Obviously, we need to have a high degree of confidence that we can freely use the name around the world if we are going to use it to replace some as well known as Java EE. Once we have a short list of potentials we will be starting a community vote to help arrive at a final choice.
Secondly, the code is moving from the existing Oracle-led Java EE organization on GitHub into EE4J. The first nine projects which were proposed have all been created and provisioned, and the code is being moved into them as we speak. The next step on this front will be to propose the next round of projects to move next. As I understand it, the Oracle team will be proposing the JSON-B API and JavaMail projects next.Soon after will come JAX-B, JAX-WS, JSTL, UEL, JAF, Security, JTA, Enterprise Management, Concurrency, and Common Annotations. Everyone involved strongly believes that a key factor in the success of this entire migration is the rapid creation of a diverse and engaged open source community around this code, so we are moving as rapidly as possible to get these projects up and running.
We want to demonstrate to the world that these projects are capable of shipping. Therefore the short-term objective is to have the EE4J project ship a Java EE 8-compliant release as quickly as possible: i.e. a Java EE 8 certified release of Eclipse Glassfish and related projects. There are a couple of positive reasons for doing this:
It demonstrates that the EE4J projects are fully functional as open source projects, and that they and the PMC can run through the full process of a release under the auspices of the Eclipse Foundation and the Eclipse Development Process.
It gets downloadable code that users and adopters can access and run from EE4J as quickly as possible. Creating an ecosystem of developers and companies using this code is important, and the sooner we start the better.
A comment on the API projects that are moving over: several have asked on the mailing lists if the fact that the source has moved means that we can start changing the APIs directly in the EE4J projects. The short answer is “please, not quite yet”. There are several reasons for that:
We want to focus in the short term on shipping an EE 8 compliant release. So the fewer moving parts while we’re doing that, the better.
There is going to be a new spec process that is going to be managing the evolution of these APIs in the future, and it hasn’t been set up yet.
As has been discussed in several venues, this new spec process is going to be bootstrapped with some rules around the continued use of the javax namespace. We’re still working on what those rules are.
In the meantime if you really want to start prototyping some new APIs you are always free to fork the repos on GitHub.
Finally, we are working on establishing an Eclipse Foundation working group to provide a member-driven governance model for the EE4J community. Working groups are consortia which complement the Eclipse open source projects. Community-driven open source projects are great for a lot of things, but don’t do well with business and ecosystem topics such as marketing, developer outreach, branding, specifications, compliance programs, and the like. The first step in creating a working group is to write its core governance charter. We hope to have a draft of that available for review by the end of the month as well. My next blog post will provide some additional information and background on that topic.
Released this past summer, JPA 2.2 delivered some frequently requested enhancements, especially by providing better alignment with Java 8 features, such as support for the Date and Time API and the retrieval of a query result as a Stream.

















 [LIVE from
[LIVE from  The
The